
In this post, I will write about my master’s thesis project (2013). Its title is “Artificial Intelligence in Games: Developing a game partner using natural language generation.”
My thesis director was Luciana Benotti (benotti@famaf.unc.edu.ar).
The goal of this work is to design and implement an agent that generates hints for a player in a first-person shooter game. The agent is a computer-controlled character who collaborates with the player to achieve the goal of the game. It uses state-of-the-art reasoning techniques from the area of artificial intelligence planning to come up with the content of the instructions. Moreover, it applies techniques from the area of natural language generation to generate the hints. As a result, the instructions are both causally appropriate at the point in which they are uttered and relevant to the goal of the game.
What is this all about?
Most video game tutorials have a fixed script that must be followed by the player. We propose a way to produce tutorial scripts automatically that will change according to the player’s behavior and changing the environment. We will use Planning and Natural Language generation techniques.
Why do we do this?
The player’s decision-making process is nondeterministic. He is unpredictable, autonomous, and has free will. For example, in the next picture, the player can choose to skip the tutorial if he wants.

Natural language generation can offer techniques to help us to guide the player in the environment. It can be applied to tutorials, RPGs, educational games, GPS, etc
What NLG can offer?
Natural Language Generation is a subfield of Artificial Intelligence. Its input is a text in a format that human beings cannot understand and it transforms that text into something understandable.
For example, in the next picture, you can see a 3D environment. We process the environment and produce the instruction “Push a red button” that is given to the user.
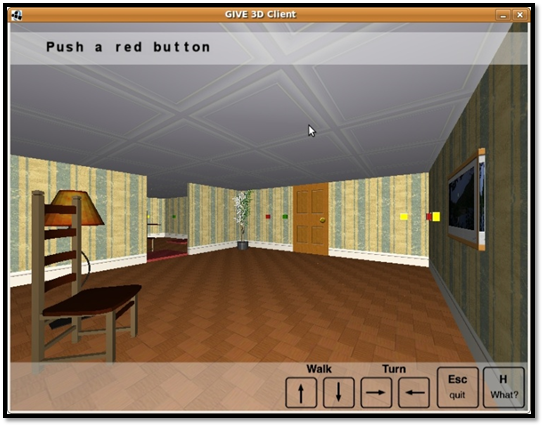
Natural Language Generation has 3 problems to solve:
- Content determination through planning
- Referring expressions generation
- Common Ground
Content determination through planning
In this step, you need to decide what kind of information are you going to communicate to the player. Your input is a physical description of the environment, then you use a planner to build a plan. For example, in the next picture, the player needs to go out of the building. The planner will receive the 2D environment representation (room, objects in the room, doors information, etc. properly) and will build a path from the player’s position to the last door’s position.

Referring expressions generation
Once a plan is built, we need to take into account objects in the environment to guide the player. In this step, we provide algorithms to describe objects. For example, in the next picture, we describe the next goal using color properties and the word “button” that is easily understandable by the player.
Common Ground
Common ground is the shared knowledge between the player and the agent (which generates the instructions). In this context, both can “talk” about something without needing to mention it explicitly. For example, in the next picture, you can see that the agent gives the instruction “Click it” to the player. In its common ground, both know that they are talking about a button, and not another kind of object.

Natural Language Generation Architecture

Garoufi & Koller (2010) proposed to unify these 3 problems into a planning problem. This integrates correctly with a small and discrete environment, but not in open environments where players can move freely in 3 dimensions.
Stone et al (2003) proposed to merge Content Determination and Microplanning, but that did not work either.
We proposed to use planning techniques only for Content Determination, while we use more traditional techniques for Microplanning and Surface Realization.
The Game
We developed an FPS game with C++ and Irrlicht engine. We used artificial intelligence techniques like path-finding techniques (like A*) and state machines. The enemy will kill the player when it finds him. In the game, we have a single enemy, rays to collect, ammunition, health items, and venom items. The player can walk, jump, use ladders, shoot and collect items.

To win this game you need to kill the creature. It is invulnerable at the beginning, but you need to collect a sequence of power rays in order to disable its invulnerability.
How does the agent guide us?
First, the planner generates a plan according to the environment. For example, the plan could be that the player collects a blue ray in front of him. Then the planner will generate a path from the player to the blue ray (Content determination through planning).
Then we use Referring Expression generation to emit an instruction. Given the distance to the ray and player orientation to the item, we emit the instruction “Do you see that ray in front of you?”

Then, suppose the player walks to the ray. As the blue ray is in the Common Ground shared by the player and the agent, we can use a pronoun to refer to the blue ray. Then, the agent can emit the instruction “Pick it up”

How does the agent generate a plan?
We use the Fast Forward (FF) planner developed by Joerg Hoffman (2005). We did a lot of different tests with state-of-the-art planners, and this one was the best by far.
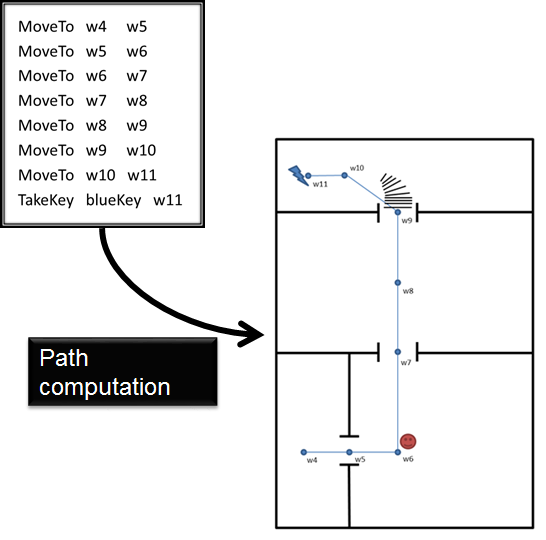
The agent must compute a plan that will be used to verbalize instructions to the player. We can see in the following picture, a plan’s fragment. For example, the first instruction is to move from waypoint 4 to waypoint 5, and the last instruction is to collect the blue ray that is located at waypoint 11.

This planner needs the sequence and positions of the different rays, waypoints positions and their adjacencies, and current player and enemy state (health, ammunitions, etc)
How does the agent use the plan?
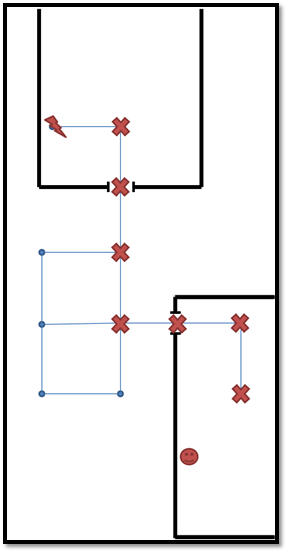
Once the agent has a plan, it needs to build a path towards the goal, in this case, to pick up the blue ray. In the next picture, we can see the path. Now the agent must decide what instruction to say next. Suppose that the player moved from waypoint 4 to waypoint 5 as we can see in the picture. We cannot verbalize each step because it would result in a very repetitive and restrictive game partner. So we made the content determination process dependent on the actions whose waypoints are directly visible to the player or visible by turning around on his current positions, we will say these waypoints are visible at 360 degrees around the player. We can see a door at waypoints 5 and 7 and stairs at waypoint 9.
In the next picture, we can see the imaginary path in the 3D world. We can see that the agent referred to the stairs because these are further in the path than the others.

When do we need to recompute the plan?
- Replanning due to unpredictable player behavior
In this case, the agent will replan when all waypoint that belongs to the current plan are not visible at 360 degrees around the player. That visibility is the common ground between the player and the agent.
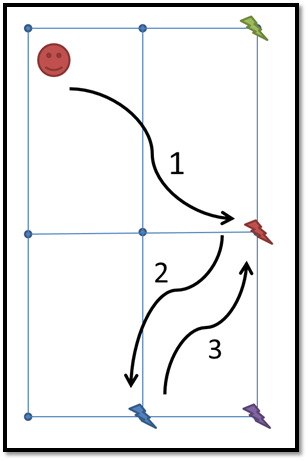
We need to collect red ray, and a plan must be generated.
A plan is generated (shortest path to red ray)

These are all visible waypoints at 360 degrees around the player.

As the player has unpredictable behavior, he can decide to go to another room instead (ignoring agent instructions). These are new visible waypoints at 360 degrees around the player.

As any of them belongs to the original plan’s waypoints, the planner needs to generate a new plan (and then, a new path too)
- Replanning due changing environment
In this case, the agent will replan when the rays’ position in the environment changes in a non-deterministic way.
Suppose the player should collect 3 rays in the following order (red, blue, red)
Once the player collects a ray, it is repositioned at a random waypoint on the map. Then if the player collected red and blue ray, a possible scenario is shown in the following picture. As you can see, red and blue rays changed their positions, and then the original plan became invalid because the environment changed in a non-deterministic way.

Evaluation
We tested 2 agents:
- Agent that generated instructions that were shown as text in the screen
- Agent that generated instructions that were given verbally (through audio)
Both systems were tested by gamers, that did not know the game or its environment, and we evaluated 2 kinds of metrics (objectives and subjective)
Objective metrics
- Recollected by the system in real-time
- Successful instructions, serious faults, and minor faults
- Game time and instruction completion time
- Total number of instructions
Subjective metrics
- Recollected post-game through a questionnaire
- Satisfiability and fun
- Agent support for the completion of the game
Results
We gathered 20 volunteers who played the game on their own. All were male, gamers and they had an average age of 20 years old. We used objective and subjective metrics to evaluate the system. The objective metrics were collected by logging the player’s behavior. The picture shows the objective metrics related to instruction generation. An instruction is considered successful if the player did exactly what the system asked him to do, a minor fault if the player deviated from the instruction without causing replanning, and an instruction is a serious fault if the agent had to replan after uttering it. We can see that approximately 60% of the instructions were successful.
Note: Red are serious faults, Light Blue are minor faults, and Green are successful instructions.
- Most instructions were successful
- Few serious faults
- Most minor faults were caused by the enemy’s presence
- The second system got better results

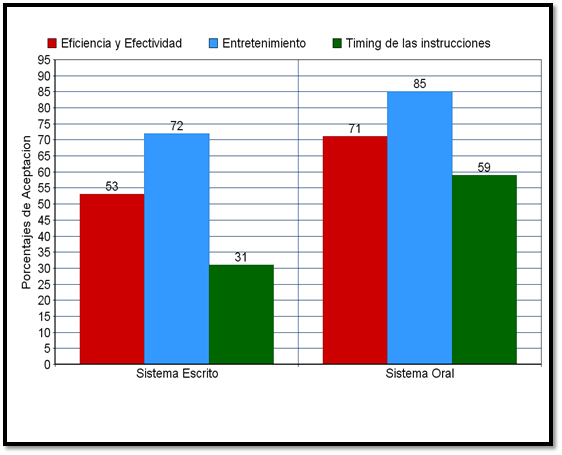
In the following picture, you can see 3 subjective metrics (Red: Efficiency and Effectiveness, Light Blue: Fun, Green: Instruction timing (if they were shown or reproduced at the right time))
The second system was much better, and both got important percentages in the Fun Efficiency and Effectiveness categories.
Future work
- Improve referring expressions to avoid ambiguous instructions
- Test the agent in more complex environments
- Replanning due enemy’s presence
Presentations
This work was presented in:
- Workshop Argentino de Videojuegos (WAVI) – 2010 – Buenos Aires, Argentina
- Artificial Intelligence and Simulation of Behaviour (AISB) 2013 – York, England

Leave a comment